![]()
Image models
Table of Contents
Image models
Transfer learning
In the previous notebook, we discovered how to handle image data efficiently using PyTorch’s Dataset and DataLoader tools. We learned to organize image data in folder structures, apply transformations on-the-fly, and load batches of images for training.
Now that we know how to prepare and load image data, the next step is to learn about machine learning models specifically designed for images. In this notebook, we will explore Convolutional Neural Networks (CNNs) and transfer learning -powerful techniques that exploit the spatial structure of images to achieve state-of-the-art results in computer vision tasks.
Image models
Until now we have used MLPs (Multi-Layer Perceptrons). MLPs are fully connected networks that expect their input as a 1D tabular dataset -meaning all data must be flattened into a single vector. When we flatten 2D image data into a 1D array, we lose the spatial structure of the image. In the previous example, we had to flatten the data, which results in:
[1]:
import torch
from torch import nn
import torchvision
import torchvision.transforms as transforms
BATCH_SIZE = 10
# Load CIFAR-10 dataset
transform = transforms.ToTensor()
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) # download must be True if is the first time you execute this notebook
# Load the entire dataset into memory
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=False)
images, labels = next(iter(trainloader))
print(images.shape)
torch.Size([10, 3, 32, 32])
/Users/miquelmn/Desenvolupament/01 - Docencia/AppOC/.venv/lib/python3.12/site-packages/torchvision/datasets/cifar.py:83: VisibleDeprecationWarning: dtype(): align should be passed as Python or NumPy boolean but got `align=0`. Did you mean to pass a tuple to create a subarray type? (Deprecated NumPy 2.4)
entry = pickle.load(f, encoding="latin1")
[2]:
from matplotlib import pyplot as plt
import numpy as np
plt.subplot(1, 2, 1)
plt.title("Image")
plt.imshow(images[0].permute((1, 2, 0)))
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(np.hstack(([images[0].flatten()] * 300)).reshape(300, -1), cmap="Greys"); # To improve the width
plt.yticks([]);
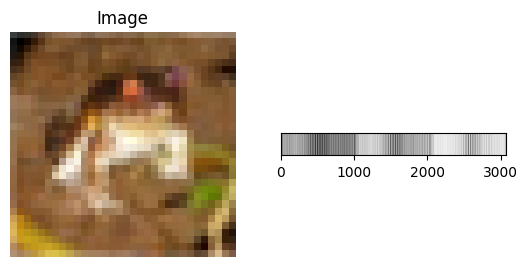
As you can see it we make a complex problem even worse. Now that we’re working with image we need models that can understand spatial patterns in images -such as edges, textures, and shapes. This is where Convolutional Neural Networks (CNNs) come in.
CNNs are a special class of neural networks designed specifically for processing grid-like data, such as images. Unlike traditional fully connected networks, CNNs take advantage of the 2D structure of images. They can recognize patterns that occur in small regions of an image and reuse that knowledge across the whole image. They were first introduce in the 80s by LeCun et al. alongside the MNIST dataset. A CNN has two main
parts:
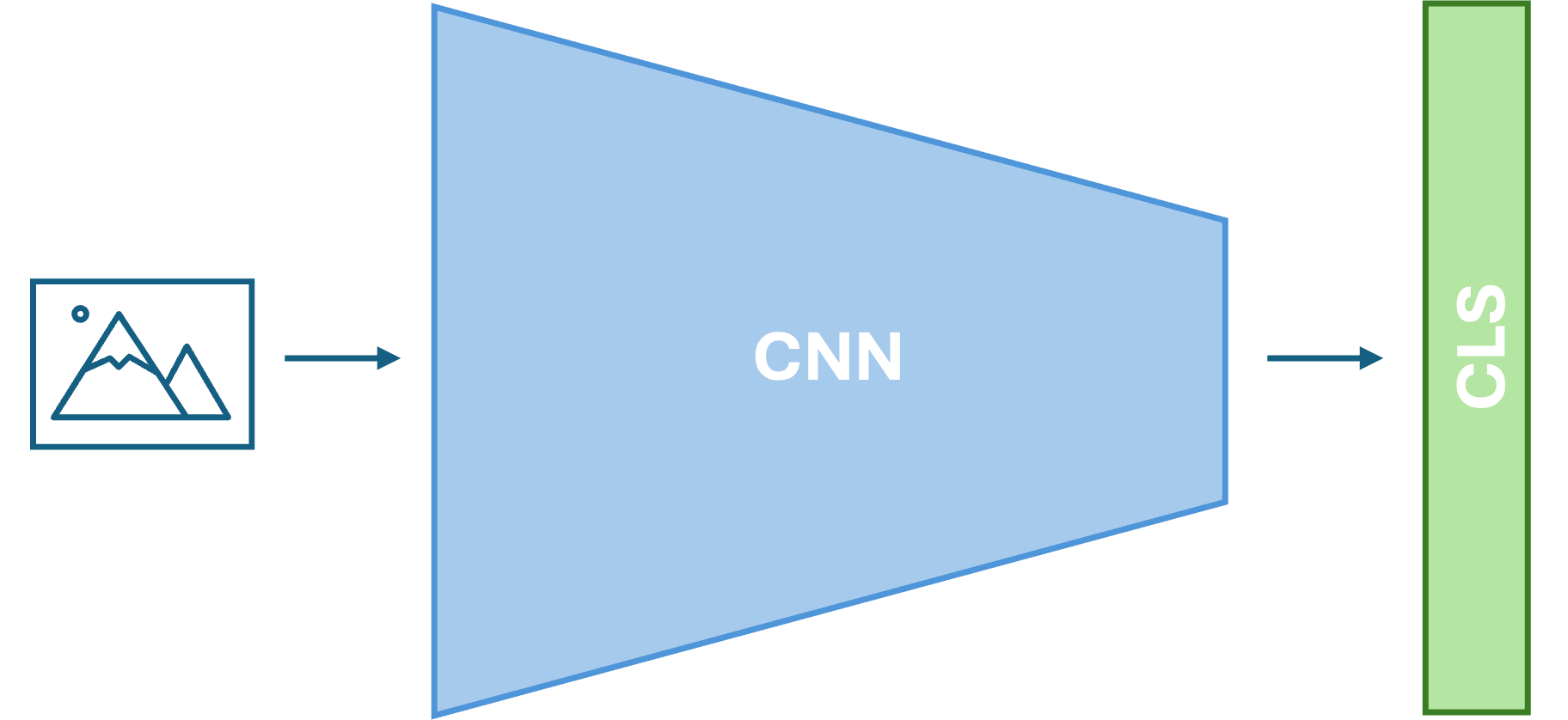
Key Building Blocks of a CNN
Convolutional Layers: These layers use learnable filters (kernels) that slide over the input (e.g., an image) to extract local features such as edges, textures, or shapes. Each filter generates a corresponding feature map that highlights the presence of specific patterns across the spatial dimensions.
Pooling Layers. These layers downsample the feature maps by summarizing small regions (e.g., taking the max value). Pooling helps reduce the spatial size and the number of parameters, making the model faster and more robust.
Predictor. We can use any machine learning model after the convolutional part. We usually use a MLP.
The most important thing to take into account: The bigger the better!
Let’s load our first CNN!:
[ ]:
import torchvision.models as models
# Load pretrained ResNet50 model
model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
model.eval() # Set to evaluation mode (disables dropout, batch norm, etc.)
TorchVision is an official library that is part of the PyTorch ecosystem. It provides:
Pre-trained CNN Models (
torchvision.models): Access to state-of-the-art architectures pre-trained on ImageNet, ready to use out-of-the-box:ResNet,VGG,Inception,DenseNet,EfficientNet,MobileNet,Vision Transformers, and many moreModels come with their pre-trained weights already downloaded and loaded
You can easily switch between different architectures:
models.resnet50(),models.vgg16(),models.efficientnet_b0(), etc.
Image Transforms (
torchvision.transforms): A complete pipeline for image preprocessing and data augmentationResizing, cropping, rotating, flipping, color adjustments, etc.
Composition of multiple transforms for efficient data pipelines
Datasets (
torchvision.datasets): Easy access to popular computer vision datasetsMNIST,CIFAR10,CIFAR100,ImageNet,COCO, and more
In the code above, we used torchvision.models.resnet50(weights=...) which:
Automatically downloads the pre-trained ResNet50 model architecture
Loads the weights trained on ImageNet (1000 classes, 14M images)
Gives us a model ready for immediate inference or fine-tuning on our own tasks
This is the power of torchvision -it abstracts away the complexity of downloading, managing, and loading pre-trained models, making transfer learning accessible to everyone.
We must adapt the images to the model!
[ ]:
# Prepare ImageNet normalization transform
imagenet_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# Get a sample image and prepare it
sample_image = images[0].clone() # Take first image from batch
sample_image_normalized = imagenet_transform(sample_image)
sample_input = sample_image_normalized.unsqueeze(0) # Add batch dimension
[ ]:
# Make inference
output = model(sample_input)
top_probs, top_classes = torch.topk(output, 5)
print(top_classes)
To understant the output we must check the Imagenet class list.
Exercise
Load an image from your compute, apply the transformer and make a prediction with the model. It is correct?
Note: To load an image you can use the library PIL:
from PIL import Image
img = Image.open(<path to image>)
[ ]:
#TODO
Transfer learning
Transfer Learning: Plug and Play
The beauty of pre-trained models is transfer learning -you can use a model trained on ImageNet for your own task:
The Superpower of Transfer Learning
Speed: Train in minutes or hours instead of weeks
Accuracy: Start from learned features, not random weights
Small Datasets: Works well even with limited labeled data
Easy to Use: Load, adapt, train -just a few lines of code
This is why pre-trained models are a game-changer in computer vision. Whether you’re classifying animals, detecting objects, or segmenting images, pre-trained models provide an incredible starting point.
Let’s see how we can do it. We will modify our ResNet50 to work with CIFAR10. There are a set of steps we must do:
Load the model and change the last layer. This will make that the prediction is the one we desired:
[ ]:
# Fine-tune ResNet50 on CIFAR10
# Load pretrained ResNet50
resnet_finetuned = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
# Modify the final classification layer for CIFAR10 (10 classes instead of 1000)
num_classes_cifar10 = 10
resnet_finetuned.fc = torch.nn.Linear(resnet_finetuned.fc.in_features, num_classes_cifar10)
We freeze the original layers. When we train the model we want that the first layers remain the same. The first layers detect general patterns (lines, curves, color, etc.).
[ ]:
# Strategy: Freeze early layers, fine-tune later layers
# Early layers capture general features, later layers are task-specific
for name, param in resnet_finetuned.named_parameters():
if "fc" not in name:
param.requires_grad = False # Freeze early layers
We train the model. It is the first time to train a CNN it have some differences.
First we want to use our GPU, because it is more computationally intensive train a CNN than a MLP.
[ ]:
# Move to device and set to training mode
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
resnet_finetuned = resnet_finetuned.to(device)
resnet_finetuned.train()
Summary: Loss Functions in Machine Learning
A loss function (or cost function) is a mathematical tool used to measure the «distance» between a model’s predictions and the actual target values. The goal of training is to minimize this value to improve accuracy.
Core Functions & Use Cases
Category |
Loss Function |
Best For… |
|---|---|---|
Classification |
Cross Entropy |
Multi-class tasks (most common). |
Classification |
Binary Cross Entropy |
Two-class tasks (Yes/No). |
Regression |
Mean Squared Error (MSE) |
General regression; penalizes large errors. |
Regression |
Mean Absolute Error (L1) |
Data with outliers; more robust. |
Key Takeaways
Optimization: Optimizers use the gradients of the loss function to adjust model weights.
Numerical Stability: In PyTorch, using
BCEWithLogitsLossis preferred over a manual Sigmoid + BCE combo to prevent mathematical errors.Data Characteristics: The choice of loss should be driven by your data; for instance, use L1 Loss if your dataset is noisy or contains many outliers.
Task Alignment: Classification typically relies on probability-based losses, while regression relies on distance-based metrics.
In our fine-tuning example above, we used torch.nn.CrossEntropyLoss() because CIFAR10 is a multi-class classification task with 10 classes.
[ ]:
# Define loss function and optimizer
loss_fn_finetuned = torch.nn.CrossEntropyLoss()
# Use lower learning rate for fine-tuning (we're starting from good weights)
optimizer_finetuned = torch.optim.Adam(
resnet_finetuned.parameters(),
lr=0.001
)
We must adapt our data to ImageNet so we load again the dataset and dataloader using the Imagenet transform operations, previously defined.
[ ]:
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=imagenet_transform) # download must be True if is the first time you execute this notebook
# Load the entire dataset into memory
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=False)
/Users/miquelmn/Desenvolupament/01 - Docencia/AppOC/.venv/lib/python3.12/site-packages/torchvision/datasets/cifar.py:83: VisibleDeprecationWarning: dtype(): align should be passed as Python or NumPy boolean but got `align=0`. Did you mean to pass a tuple to create a subarray type? (Deprecated NumPy 2.4)
entry = pickle.load(f, encoding="latin1")
The CNN Training Loop
The training loop is the core of the learning process. Here’s what happens in each iteration:
Step-by-Step Breakdown
For each epoch (complete pass through the entire dataset):
Initialize metrics (loss, accuracy) to track performance
for epoch in range(epochs_finetune): running_loss = 0.0 running_acc = 0.0
For each batch from the DataLoader:
Forward Pass: Feed images through the CNN to get predictions
outputs = model(images) # CNN predicts classes
Compute Loss: Calculate how wrong the predictions are compared to true labels
loss = loss_fn(outputs, labels) # Quantify error
Backward Pass: Compute gradients using backpropagation
optimizer.zero_grad() # Clear previous gradients loss.backward() # Compute gradients via chain rule
Optimizer Step: Update model weights to reduce loss
optimizer.step() # Move weights in direction that reduces loss
Track Metrics: Update running loss and accuracy
running_loss += loss.item() _, predicted = torch.max(outputs, 1) # Get highest probability class running_acc += (predicted == labels).sum().item() / labels.size(0)
After each epoch:
Calculate average loss and accuracy
Print progress
Repeat for next epoch
Key Concepts
Forward Pass: Data flows through the network to produce predictions
Loss Computation: Measures how far predictions are from ground truth
Backward Pass: Computes gradients showing how to adjust weights
Gradient Descent: Optimizer uses gradients to update weights in the direction that reduces loss
Epochs: Complete passes through the entire dataset; multiple epochs allow the model to learn iteratively
This loop repeats thousands of times, gradually improving model accuracy through incremental weight adjustments.
[ ]:
# Fine-tuning loop
epochs_finetune = 5
for epoch in range(epochs_finetune):
running_loss = 0.0
running_acc = 0.0
for batch_idx, (images, labels) in enumerate(trainloader):
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = resnet_finetuned(images)
loss = loss_fn_finetuned(outputs, labels)
# Backward pass
optimizer_finetuned.zero_grad()
loss.backward()
optimizer_finetuned.step()
# Metrics
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
running_acc += (predicted == labels).sum().item() / labels.size(0)
if (batch_idx + 1) % 100 == 0:
avg_loss = running_loss / (batch_idx + 1)
avg_acc = running_acc / (batch_idx + 1)
print(f"Epoch [{epoch+1}/{epochs_finetune}], Step [{batch_idx+1}/{len(trainloader)}], "
f"Loss: {avg_loss:.4f}, Accuracy: {avg_acc:.4f}")
avg_loss = running_loss / len(trainloader)
avg_acc = running_acc / len(trainloader)
print(f"Epoch {epoch+1}/{epochs_finetune} completed - Loss: {avg_loss:.4f}, Accuracy: {avg_acc:.4f}\n")
print("Fine-tuning complete!")
The training loop have become more complex, with a second loop, however, to do a prediction with an already trained model is as easy as in more simple models:
[ ]:
resnet_finetuned(images)
Saving and Loading Model Weights
In practice, trained model weights are usually shared separately from the code. This is done for several reasons:
Large file sizes: Pre-trained models can be very large (hundreds of MB to GBs), making it impractical to include them in code repositories.
Easy distribution: Weights can be hosted on separate servers or repositories (like HuggingFace, PyTorch Hub, Kaggle) and downloaded on-demand.
Version control: Code and weights can be versioned independently.
PyTorch provides simple methods to save and load model weights:
``torch.save()``: Saves model state (weights) to disk
``torch.load()``: Loads model state from disk
``.state_dict()``: Returns a dictionary of all model parameters
This allows you to train a model once, save its weights, and then load them in any environment without retraining.
[ ]:
# Save the trained model weights
torch.save(resnet_finetuned.state_dict(), 'resnet_finetuned_weights.pth')
# Load the model weights into a new model
model_loaded = models.resnet50(pretrained=False)
model_loaded.fc = nn.Linear(model_loaded.fc.in_features, 10) # Adjust for CIFAR10
model_loaded.load_state_dict(torch.load('resnet_finetuned_weights.pth'))
Exercise
Hopefully now our method is working with CIFAR10. With this exercise we will test if that is true:
Create a dataset and a dataloader for the test set of CIFAR10.
Obtain the accuracy of the previosly trained model. Is good enough?
In the following link you fill find a ResNet50 weight file. Load it and verify its accuracy. (Weights download from here). You will have to adapt our model to this weights.